如果有看我之前文章的朋友會知道,我對於 Docker 實戰六堂課 這本書讚譽有加,因為它不僅理論基礎紮實,還提供了非常實用的實作範例,幫助讀者快速掌握 Docker 和 Linux 的核心概念與應用。受到啟發,我寫了 從 Linux 基礎實現 Docker Bridge 網路:一步步理解容器通訊 (1) 系列文章。
上週小賴老師舉辦了一場直播,探討該書中未提及的容器資源限制,並進行了相關實驗。內容依然簡潔、精彩且實用。因此,我打算以該直播內容為基礎,撰寫我的理解、延伸內容與實作過程。
如果懶得閱讀文字,可以直接觀看小賴老師的直播回放 - 探索容器資源限制
命名空間(Namespaces)是 Linux 核心提供的一種機制,用於隔離不同進程之間的全局系統資源。Docker 利用以下幾種命名空間來實現容器的隔離:
簡單來說,Namespace 就像團體分組,各組(Namespace)彼此隔離,無法互相看到。Namespace 可以嵌套,類似層級分明的組織圖。不過,PID 命名空間比較特殊,因為它可以看到自己底下的子命名空間,而其他類型則無法。
透過這些命名空間,Docker 得以確保容器在進程、網路、檔案系統等方面的隔離,防止容器之間的相互干擾。目前只需要了解 Docker 和 Kubernetes 的 Namespace 都是基於這個機制來實現的。未來有機會會單獨寫一篇文章深入探討。詳情可參考 namespaces(7) — Linux manual page。
網路方面的 Namespace 實作,可參考系列文章:從 Linux 基礎實現 Docker Bridge 網路:一步步理解容器通訊 (1)。
控制群組(cgroups)是 Linux 核心提供的另一種機制,用於限制、監控和隔離進程群組對計算資源的使用。Docker 利用 cgroups 來限制容器的資源消耗,包括:
透過配置 cgroups,Docker 能防止單個容器過度消耗系統資源,確保系統的穩定性與公平性。
cgroups 版本的差異
自 cgroups 引入以來,已經發展出兩個主要版本:cgroups v1 和 cgroups v2。cgroups v2 針對 v1 的複雜性和一致性問題進行了重大改進,主要透過統一層級結構和標準化介面。雖然需要一定的遷移工作,但 v2 提供更強大的功能、更一致的行為和更簡化的管理方式,有助於提升系統資源管理的效率與可靠性。
目前一些主流的 Linux 發行版,已經陸續預設啟用 cgroup v2,例如:
要查看 Linux 使用的 cgroups 版本,可以使用以下指令:
stat -fc %T /sys/fs/cgroup/
cgroup v2 的輸出為 cgroup2fs;cgroup v1 的輸出為 tmpfs。
更多資訊可參考:Kubernetes - About cgroup v2。
以下是補充、修正與延伸後的版本,保持內容通順、精簡且正確:
要了解 CPU 的運作方式,我們需要引入作業系統的資源分配與調度概念,特別是 CPU 的時間分配與權重調整機制。而 Memory 資源則相對直觀,但其容量限制與管理機制也需要作業系統進行控制。
特性與運作
CPU 調度
簡而言之
特性與運作
記憶體管理
memory.limit_in_bytes 或 memory.max 設定記憶體上限:
簡而言之
用表格簡單比對:
| 屬性 | CPU | Memory |
|---|---|---|
| 資源特性 | 彈性資源,可共享 | 固定資源,不可超量使用 |
| 限制機制 | 調度和優先級 | 硬性上限,觸發限制可能導致進程終止 |
| 不足時的行為 | 進程速度變慢,但可繼續執行 | 超量分配會導致應用崩潰或觸發 OOM Killer |
| 限制工具 | - cpu.max- cpu.shares |
- memory.limit_in_bytes- memory.max |
| 適用場景 | 確保公平分配,防止 CPU 過載 | 防止記憶體洩漏,確保系統穩定性 |
實驗環境如下:
- Windows host: Windows 11 Pro 23H2
- WSL Version: 2.3.26.0
- WSL Distribution: Ubuntu 22.04.5 LTS
雖然我的 WSL 使用的是 Ubuntu 22.04 發行版,但預設卻是 cgroup v1:
stat -fc %T /sys/fs/cgroup/
#
tmpfs
這點在 KinD 的 Issues 中有提到。在 wsl-cgroupsv2 專案的說明文件中提到,WSL 2 默認運行在一種混合模式下,支持 cgroup v1 和 v2。這可能會導致在使用某些容器技術(如 Docker 或 Kubernetes)時出現問題。
自 Linux v5.0 起,Linux kernel boot option cgroup_no_v1=<list_of_controllers_to_disable> 可用於停用 cgroup v1 層級架構。根據 WSL 文件,我們必須在 %UserProfile%\.wslconfig 檔案中新增:
[wsl2]
kernelCommandLine = cgroup_no_v1=all
儲存後,使用以下指令重啟 WSL:
wsl --shutdown
wsl -d Ubuntu-22.04
再次查詢 cgroup 使用版本:
stat -fc %T /sys/fs/cgroup/
#
cgroup2fs
切換到 root 使用者,來到 /sys/fs/cgroup 資料夾,查看內容:
$ sudo su
#
root@vince987:/#cd /sys/fs/cgroup
#
root@vince987:/sys/fs/cgroup# ls
#
cgroup.controllers cgroup.threads init.scope sys-kernel-debug.mount
cgroup.max.depth cpu.stat io.stat sys-kernel-tracing.mount
cgroup.max.descendants cpuset.cpus.effective memory.reclaim system.slice
cgroup.procs cpuset.mems.effective memory.stat user.slice
cgroup.stat dev-hugepages.mount misc.capacity
cgroup.subtree_control dev-mqueue.mount sys-fs-fuse-connections.mount
從檔名可以看出,它可以定義諸如 cpu、memory、io 等計算資源。
我們在這個目錄下建立新資料夾 test_group,等於建立一個新的 group 來控制資源:
root@vince987:/sys/fs/cgroup# mkdir test_group
#
root@vince987:/sys/fs/cgroup# cd test_group/
#
root@vince987:/sys/fs/cgroup/test_group# ls
cgroup.controllers cpu.stat hugetlb.2MB.current memory.oom.group
cgroup.events cpu.weight hugetlb.2MB.events memory.reclaim
cgroup.freeze cpu.weight.nice hugetlb.2MB.events.local memory.stat
cgroup.kill cpuset.cpus hugetlb.2MB.max memory.swap.current
cgroup.max.depth cpuset.cpus.effective hugetlb.2MB.rsvd.current memory.swap.events
cgroup.max.descendants cpuset.cpus.partition hugetlb.2MB.rsvd.max memory.swap.high
cgroup.procs cpuset.mems io.stat memory.swap.max
cgroup.stat cpuset.mems.effective memory.current misc.current
cgroup.subtree_control hugetlb.1GB.current memory.events misc.max
cgroup.threads hugetlb.1GB.events memory.events.local pids.current
cgroup.type hugetlb.1GB.events.local memory.high pids.events
cpu.idle hugetlb.1GB.max memory.low pids.max
cpu.max hugetlb.1GB.rsvd.current memory.max rdma.current
cpu.max.burst hugetlb.1GB.rsvd.max memory.min rdma.max
僅僅是在這建立資料夾,cgroup 就會自動幫我們做初始化。
打印 cpu.max 內容:
cat cpu.max
#
max 100000
這表示一個 CPU 週期是 100,000 微秒,而該 group 可以無限制地使用。
將 max 設定為 10,000,表示在 100,000 微秒的週期內,最多允許使用 10,000 微秒的 CPU 時間,即 10% 的 CPU 使用率:
root@vince987:/sys/fs/cgroup/test_group# echo "10000 100000" | tee cpu.max
#
10000 100000
實驗步驟:
htop 工具監控資源使用情況。while : ; do : ; done),這會造成一顆 CPU 核心被用滿。cgroup.procs 文件內,讓進程受到 test_group 控制。結果如下:
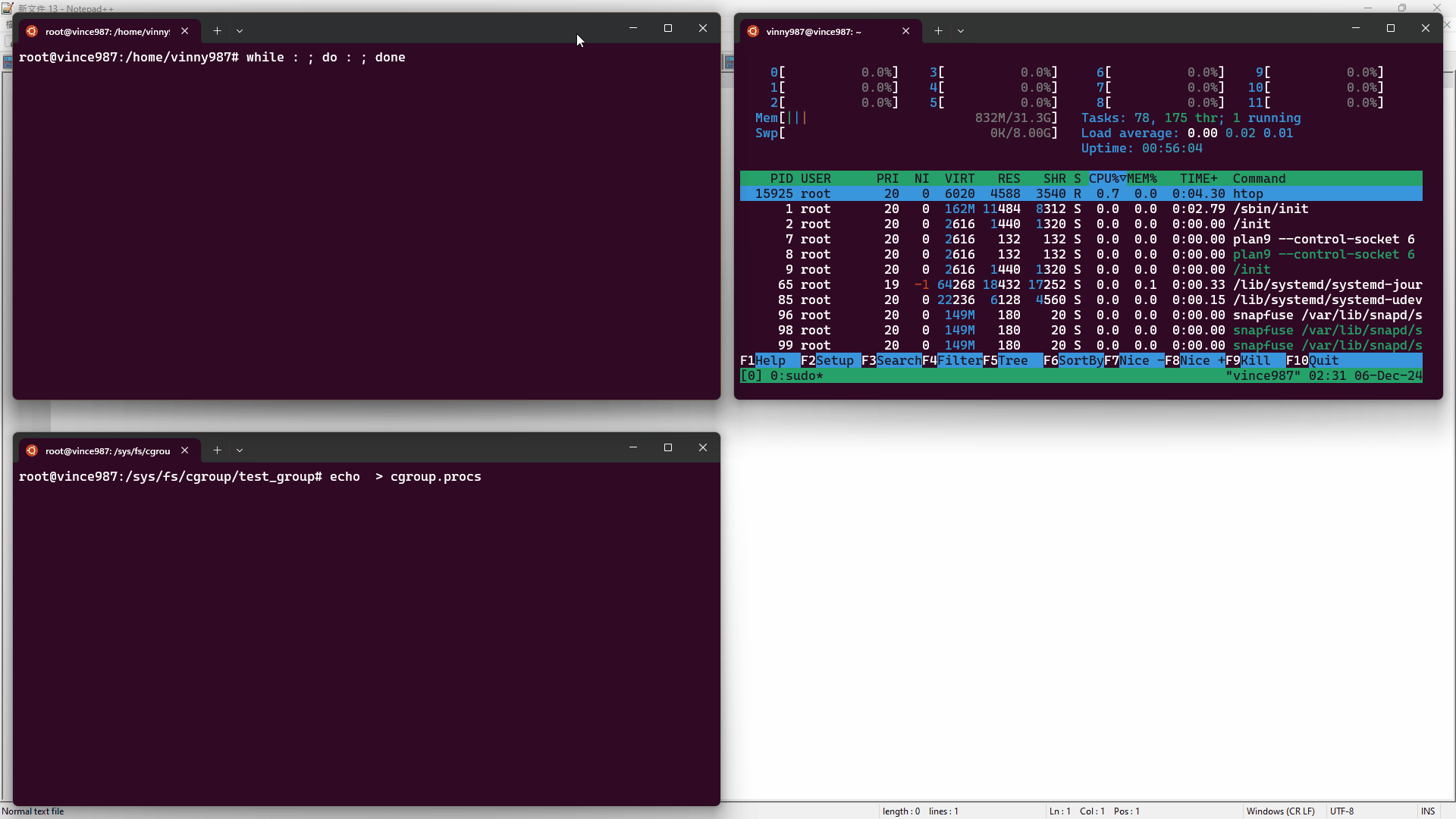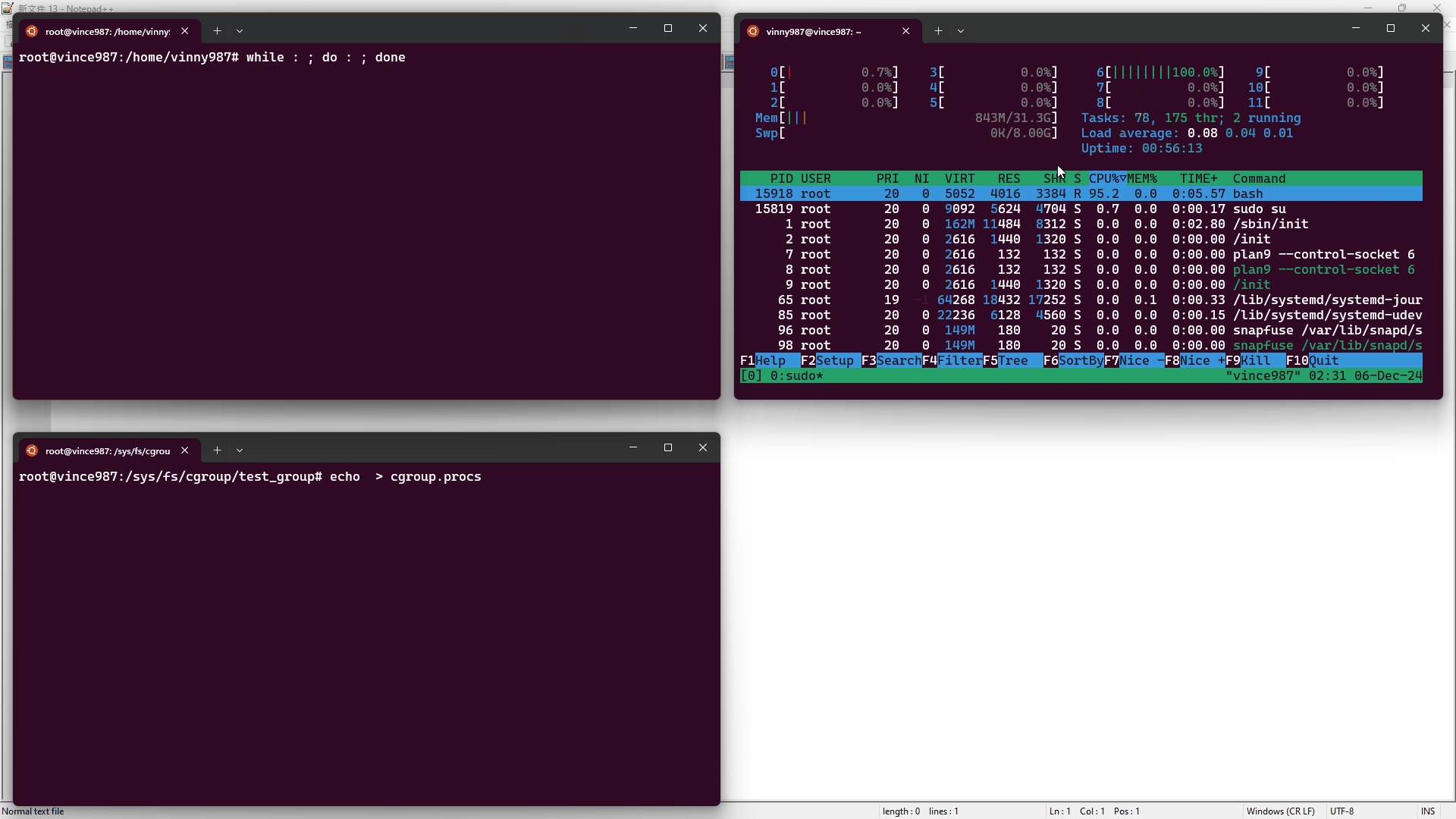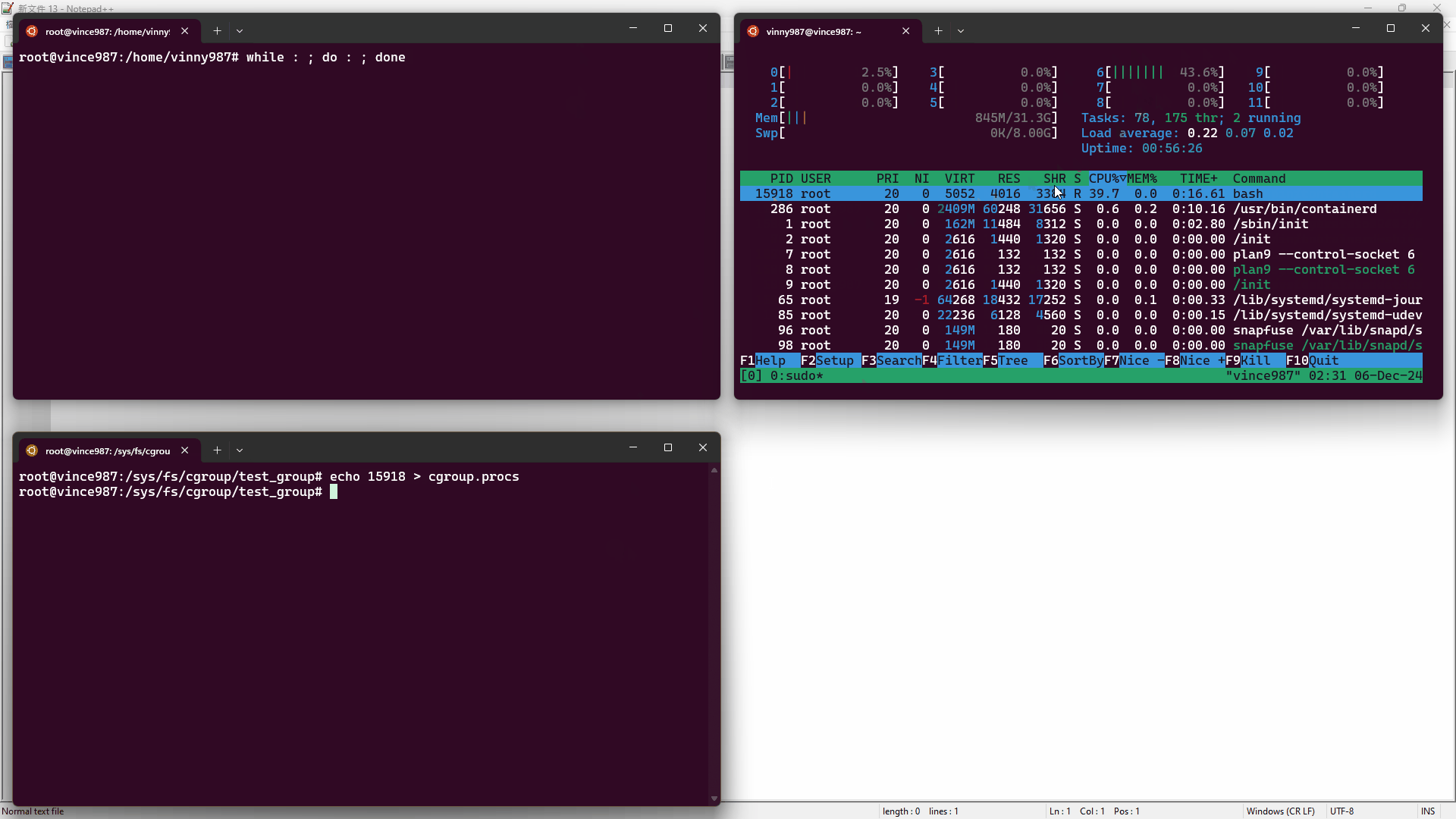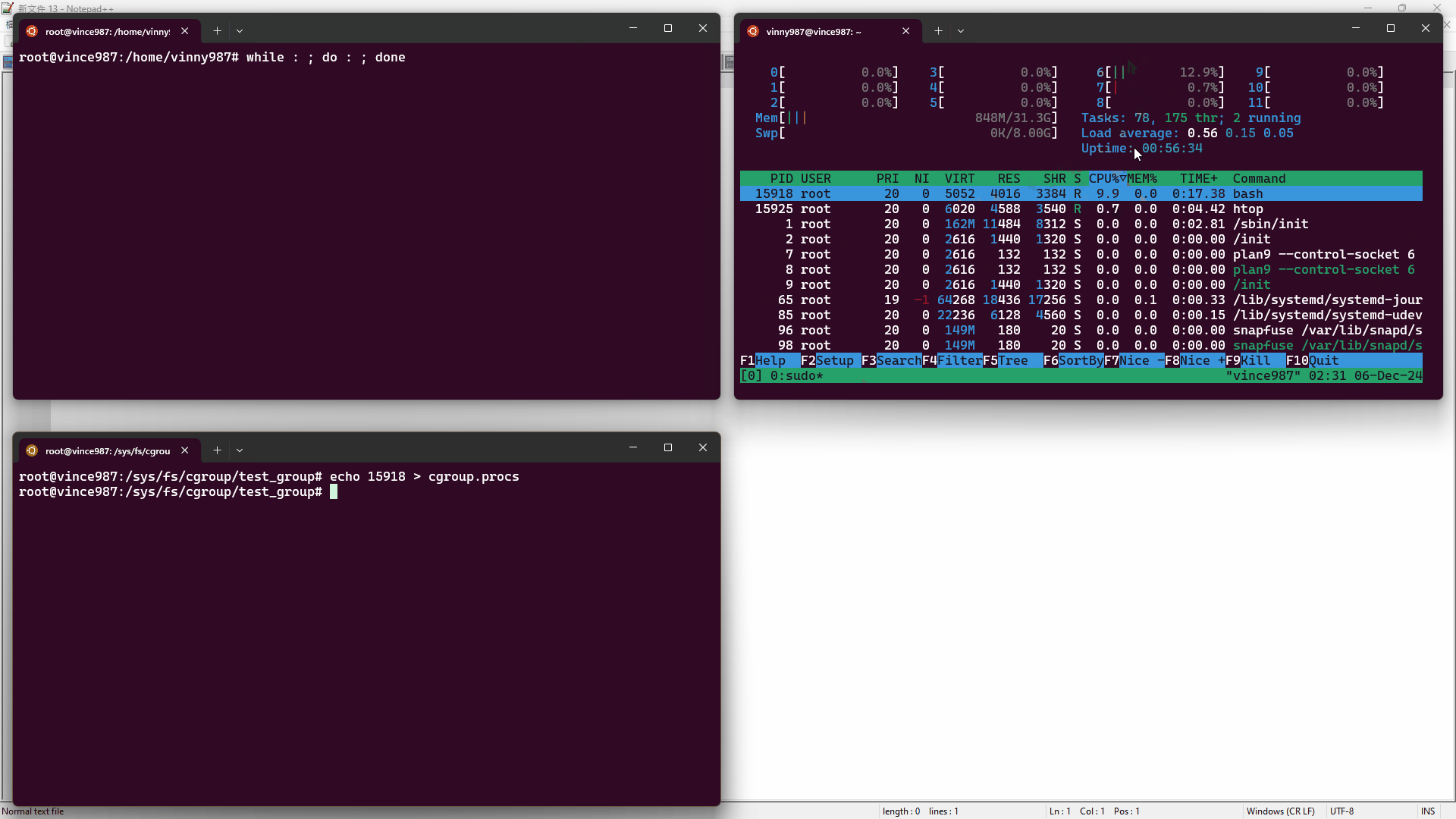
在刪除 cgroup 時,必須確保其中沒有任何進程或子 cgroup,否則刪除操作會失敗。
# 檢查是否有進程
cat /sys/fs/cgroup/test_group/cgroup.procs
# 如果有進程,移動進程到父 cgroup
for pid in $(cat /sys/fs/cgroup/test_group/cgroup.procs); do
echo $pid > /sys/fs/cgroup/cgroup.procs
done
# 刪除 cgroup
cd /sys/fs/cgroup/
rmdir /sys/fs/cgroup/test_group
建議使用現成工具(如 cgdelete)來移除 cgroup,等效於上述操作:
# 安裝工具
sudo apt install cgroup-tools
# 移除
sudo cgdelete -g cpu:/test_group
Memory 的限制也是差不多的做法,就不另外展示。
Linux 系統中,Namespaces 提供了進程、網路和檔案系統等多層面的隔離能力,使每個容器都像一個獨立的操作環境。cgroups 則在資源分配和限制上發揮了關鍵作用,避免單一容器過度消耗系統資源。
在實驗中,我們實現了使用 cgroups v2 來限制進程的 CPU 資源,並成功觀察到其效果,驗證了理論與實踐的一致性。
後續還有透過 Docker,來實踐和驗證資源分配和限制的特性,由於篇幅關係,就留到下一個章節繼續。
 vincentlin2447
vincentlin2447
